
밥 먹여주는 머신러닝 (1편)

당신이 몇 시간을 노력하는지만 체크한다면, 당신은 시급으로 계산되는 노동자에서 벗어나지 못할 가능성이 크다!

인문학 전공자가 취직할 수 있는 곳은 고대 그리스밖에 없다
취업을 준비하려면 직무부터 정하라는, 어쩐지 모순적이지만 그럴듯한 말에 무작정 "마케팅"을 직무로 정하고 준비를 시작했다. 그런데 마케팅 직무의 한 부분인 데이터 분석에 흥미를 느끼게 되어, 어느샌가 머신러닝, 통계학, 파이썬을 공부하고 있는 나를 발견했다. 그렇게 1년 반가량, 쌩판 먼 나라 이야기였던 공대 컴퓨터공학과에서 인공지능을 연구하는 랩실을 목표로 대학원 준비가 시작되었다. 그동안 인공지능을 기초 수학부터 딥러닝 모델들까지 공부해오면서, 아주 공대적인 학문에서 발견한 의외의 인문학적 삶의 통찰 같은 것들을 여러 번 경험했다. 이 블로그에서는, 공대의 기술적인 소재에서 얻을 수 있는 우리 삶의 인문학적인 것에 대해서 매주 글을 써서 공유할 생각이다. 첫 번째 글은 머신러닝을 공부할 때 '평가 지표'가 얼마나 예측 모델의 학습에 중요한 영향을 미치는지를 보면서, 내 뇌가 학습할 때 그 평가 지표는 과연 무엇이었으며 어떤 영향을 미쳤는지 돌이켜보며 얻은 통찰에 관한 것이다.

딥러닝(deep learning)에서 어떤 예측 모델을 훈련할 때, 양질의 데이터 못지않게 중요한 것은 '어떤 기준으로 평가할 것인지'이다. 즉, 어떤 평가 지표(metric)를 사용하여 훈련 데이터를 평가하면서 모델을 학습시킬지가 매우 중요한
것이다. 대개 기본적으로 사용되는 정확도(accuracy)는 단순히 모든 경우 중에 예측이 성공한 경우가 몇 퍼센트인지를 나타내는 지표다.
하지만 1% 미만의 극소수의 암 환자를 구분하는 예측 모델을 훈련할 때 정확도를 지표로
사용하는 것은 최악의 실수다. 예측 모델은 모든 경우에 대해 '암이 아닙니다'라고 앵무새처럼 대답만 해도 99% 이상의 정확도를 얻게 되기 때문에, (높은 정확도를 목표로 하는) 수학적 최적화 과정을 거쳐 그러한 모델로 학습될 수밖에 없다. 다시 말해 실제 암이 있는 환자들을 건강한 사람으로 분류하는 위음성(false negative)을 범하게 된다는 것이다. 따라서 이렇게 양성-음성의 비율이 극단적으로 불균형한 데이터를 가지고 모델을 훈련할
때에는, 정확도가 아니라 재현율(recall)을 평가 지표로 사용해야 한다. 재현율은, 모든 경우에 대한 예측 성공률이 아니라 '실제 암 환자 중 몇 명이나 예측했는지'를 평가한다. 쉽게 말해 암이 없는 사람을 실수로 양성으로 분류하는 경우가 좀 더 생기는
걸 감수하는 대신, 실제 환자라면 반드시 예측해내겠다는 의지로 훈련하겠다는 것이다. 병원에서는 그 높은 정확도로 1%의 암 환자 중 단 한 명도 검출해내지 못하는 모델보다, 몇몇 건강한 환자도 암이라고 오진하겠지만 결과적으로 1%의 암 환자를 대부분 검출해내는 모델이 필요한 것이다.

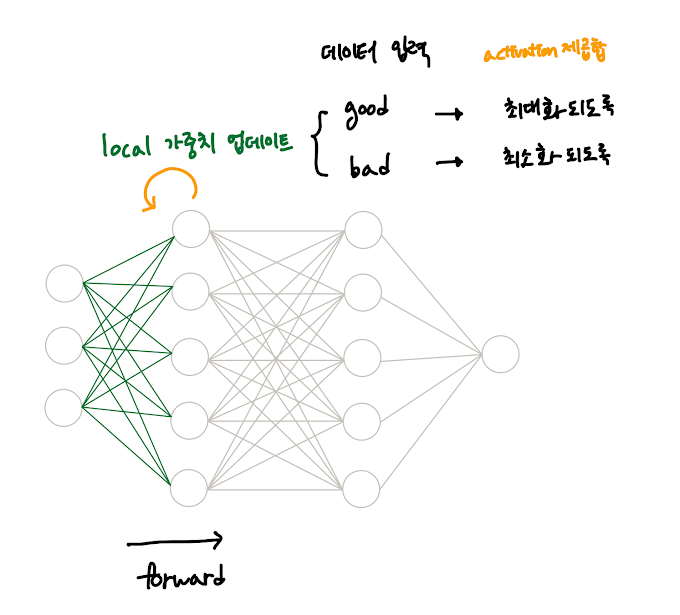
딥러닝이란 인간의 뇌의 신경망(neural network)에서 착안한 것으로, 수많은 뉴런을 층층이 쌓은 모델에 데이터를 전파시키고 (이것이 순전파이다) 결과를 역전파(backpropagation)시켜 피드백하고 수정하는 과정을 통해 학습하는 머신러닝의 일종이다. 딥러닝의 눈부신 성과에 힘입어, 이 인공신경망의 작동방식이 거꾸로 우리 인간의 뇌 구조를 이해하는데 큰
도움이 될 것이라는 신경과학적 접근방식도 크게 주목받고 있다. 우리의 뇌에서도 역시 매 순간 훈련이 일어나고 있고, "생각에 관한 생각", 즉 메타 인지를 통해 그 과정에 영향을 미칠 수 있다. 특히 공부를 할 때, 즉 학습 과정에서 사용되는 메타 인지에서 결정적인 요소는 머신러닝과
마찬가지로 '어떤 평가 지표를 사용할 것인가'이다.
평가 지표의 위력은 일상에서도 매우 쉽게 확인할 수 있다. 다이어트를 할 때 매일 몸무게를 체크한다면 체중이란 수치의 감소를 얻게
되지만, 매일 식단을 체크하고 몸매를 사진으로 기록한다면 건강과 함께 좋은 몸매를
얻는다.

뇌에서도 마찬가지로 어떤 평가 지표를 사용하느냐에 따라 뇌의 훈련이
천차만별로 달라질 수밖에 없다. 하브 에커는 『백만장자 시크릿』에서, 성공한 부자들은 시간에 따라 보상받는 것 대신 결과에 따라 보상받는 것을
선택한다고 말한다. 시간에 따라 안정적으로 보상받는 것은, 사실 시장에서 '진짜' 가치를 시험받기 두렵기에 내린 선택이란 것이다. 당신이 몇 시간을 노력하는지만 체크한다면, 당신은 시급으로 계산되는 노동자에서 벗어나지 못할 가능성이 크다. 시간을 소중히 여기는 것은 물론 좋은 태도이지만, 당신의 자기계발과 발전을 평가하는 지표로 '투입되는 시간'만을 고려한다면 당신의 모델은 '많은 시간 동안 노력하는 것'을 향해 나아갈 것이다.
하지만 당신이 '얼마나 많은 것을 이루어냈느냐'는 아웃풋을 평가 지표로 사용한다면, 당신의 학습 모델은 '많은 성과를 이루어내는 것'을 향해 나아갈 것이다. 스스로의 노력을 체크하고 더 나은 발전 계획을 수립하고자 한다면, 스터디 플래너에 공부한 '6시간'을 적으면서 뿌듯해할 것이 아니라, 그 여섯 시간 동안 도출해낸 아웃풋이 정확히 어느 정도이며 (혹시 조금 더 집중했더라면 훨씬 짧은 시간 안에 끝낼 수 있었던 것일 수도
있다), 그것이 나의 구체적인 목표의 어느 부분에 어느 만큼 발전을 이뤄냈는지 명확하게 평가하는 것이 필요하다.
★ 성과 중심의 평가 지표 사용법:
1. 이뤄낸 성과의 양을 적는다.
2. 집중력의 정도를 평가한다.
3. 특정 목표의 어느 부분에 어느 만큼 도움이 되었는지 적는다.
영어 편집자 Emily Adam 이 직접 쓴 실제 사용법 사례를 보려면 영어 포스트를 확인하세요!


![[책&강의] 직접 보고 추천하는 머신러닝 & 딥러닝 & 수학 총정리 (2022)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg4J7BS4klgeMe-qrWTi8NgyI_4TLzPs_ltwFp4591fHoi8fOXITF_0JXLzcFeN9zIMaFPfpO-PpPOl6gej6pA4uRAWBhKMna9DJsNtTW2IbnIn3a2z_xa54Oyn8evu1P0GKQpElxZgMTI/w680/ml%25EC%25B4%259D%25EC%25A0%2595%25EB%25A6%25AC.jpg)
![[M1] 맥 필수 무료 앱 총정리 2022 (똑같은 앱 왜 돈주고 써요?)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhzAyZ9Nc9lbIoU8qirm1KCVwhhyphenhyphen2YaeqPzMxU1nZeIRdrp7__aKbQQo3P-D8RGCAcRsXztowdDDdvwm7zuM-vpPmK8x2f3WgzKS8X-7E-PGcLgsj8w4xawHh7HU3VcSU0cmOaoeGBmWx4/w680/)
![[비전공자를 위한 딥러닝] 2.2 선형회귀 (2) - 오차와 비용](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjEhHlP2edVHNaiochUISyW2RIQ_K5Kdsh0gjT5Wt1vY4nH7uP_0mTNZ1suzBRmpsPOptT1n4-hJ1mOXUhY4ZvLyiywxqn_7wusQDpllIS94VPVuYbQqpCdyuhISZ2mYNQF6laTKDUk_ts/w680/%25E1%2584%2587%25E1%2585%25B5%25E1%2584%258C%25E1%2585%25A5%25E1%2586%25AB%25E1%2584%2580%25E1%2585%25A9%25E1%2586%25BC%25E1%2584%2583%25E1%2585%25B5%25E1%2586%25B8%25E1%2584%2585%25E1%2585%25A5%25E1%2584%2582%25E1%2585%25B5%25E1%2586%25BC2.jpg)
![[비전공자를 위한 딥러닝] 2.4 신경망 (2) - 가중치 행렬 한방에 이해하기](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiYj8FRyvmF70qt64R3suVR6lJdNynz2-tF5fa7T_3wE8SK3KIO1BCvwyypr5J_mlxaYkQjadrofLYsMjBbgRklxDORXoWiJdWP79otQowzIXsghxuZS9aYLhvvlMNX3NzQ3VYDdslwmbk/w680/%25E1%2584%2587%25E1%2585%25B5%25E1%2584%258C%25E1%2585%25A5%25E1%2586%25AB%25E1%2584%2580%25E1%2585%25A9%25E1%2586%25BC%25E1%2584%2583%25E1%2585%25B5%25E1%2586%25B8%25E1%2584%2585%25E1%2585%25A5%25E1%2584%2582%25E1%2585%25B5%25E1%2586%25BC2+%25281%2529+%25E1%2584%2587%25E1%2585%25A9%25E1%2586%25A8%25E1%2584%2589%25E1%2585%25A1%25E1%2584%2587%25E1%2585%25A9%25E1%2586%25AB+3.jpg)
![[비전공자를 위한 딥러닝] 3.1 소프트맥스와 크로스 엔트로피](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgTJTtjJZ-RLhpfRkWo6WHRZaHWPEgf0m3ABnwv5pjRIsDmYMHzBOZhZU9pTErx56yPDGtCjvBXgcAO4thFecCFZxLfe4Siep132JoIizjnX24cg0T37BYagZGlVOlZfBnBWJVUqNle3s0/w680/%25E1%2584%2587%25E1%2585%25B5%25E1%2584%258C%25E1%2585%25A5%25E1%2586%25AB%25E1%2584%2580%25E1%2585%25A9%25E1%2586%25BC%25E1%2584%2583%25E1%2585%25B5%25E1%2586%25B8%25E1%2584%2585%25E1%2585%25A5%25E1%2584%2582%25E1%2585%25B5%25E1%2586%25BC2+%25281%2529.jpg+%25E1%2584%2587%25E1%2585%25A9%25E1%2586%25A8%25E1%2584%2589%25E1%2585%25A1%25E1%2584%2587%25E1%2585%25A9%25E1%2586%25AB+4.jpg)
){kind=link}
18 댓글
좋은 정보네요! 잘 읽고 갑니다.
답글삭제감사합니다! 매주 포스팅할 예정이니 관심있게 지켜봐주시길 부탁드릴게요 :)
삭제형 저 글 퍼온 게 아니라 형이 연구하고 쓴 거예요? 너무 잘썼네..
답글삭제물론이죠! 감사합니다 :)
삭제분명 고급진데 나한테는 어렵..ㅜ
답글삭제좋은 피드백 감사합니다! 조금 더 이해하기 쉽고 유용한 글을 쓰겠습니다 :)
삭제잘읽었네요~ 항상 관심있게 지켜볼껭~~
답글삭제감사합니다! 기대에 맞춰 꾸준히 포스팅할게요 :)
삭제성과 중심의 평가지표가 와닿아요. 많이 배워 갑니다. 감사합니다!
답글삭제감사합니다! 잘 전달되었다니 다행이네요. 더 좋은 글로 찾아뵙겠습니다 :)
삭제삶의 평가 지표를 생각해 봐야겠네요:)
답글삭제글의 메시지가 잘 전달된 것 같아 기쁘네요! :)
삭제글 좋구만!
답글삭제앞으로도 기대할게 준호!!ㅎㅎ
감사합니다! 매주 포스팅 기대해주세요 :)
삭제블로그 명이 '국문과 공대생' 멋지네요~^^
답글삭제글을 읽고 나니 운동을 할 때에도
성과중심의 평가 지표를 가지고 하면 더
효과적일 거란 생각이 드네요.
다음주가 벌써 기대되네~~^^
감사합니다^^ 글이 유익하셨다니 뿌듯하네요! 더 좋은 글로 찾아뵙겠습니다.
삭제philgineer다운 발상이네요, 인상 깊어요! naver AI tech 글로 들어와서 최근 글들을 보고 배울 점이 많은 분인 것 같아 블로그 정독 시작합니다! 잘 기록해주셔서 정말 감사해요
답글삭제정독을 하신다니 정말 감사하네요.
삭제앞으로 더 좋은 컨텐츠로 보답하겠습니다 :)