

딥러닝은 현재 다양한 분야에 활용되고 있는데,
컴퓨터 비전(computer vision) 분야에서의 활약은 정말 대단하다고 할 수
있다. 컴퓨터 비전이란 말 그대로 컴퓨터로 시각(vision)적인 정보를 해석하고
활용하는 분야다. 앞서 다룬 이미지 분류 문제 외에도, 이미지의 특정 영역의
물체의 위치와 클래스를 찾는 객체 검출(object detection), 영수증이나
메뉴판 등의 이미지에 있는 글자들을 인식해 텍스트를 반환하는
광학 문자 인식(OCR, Optical Character Recognition) 등 다양한 문제를
해결하는 데 사용되고 있다.
이번 장에서는 이러한 분야에서 거의 필수적으로 활용되는
합성곱 신경망(CNN, Convolutional Neural Network)에 대해 간략히
살펴보도록 하자.
'2'라고 적힌 손글씨 이미지 데이터가 있다고 생각해보자.
이 데이터는 다음
그림처럼 2차원 배열의 형태로 컴퓨터에 저장된다.
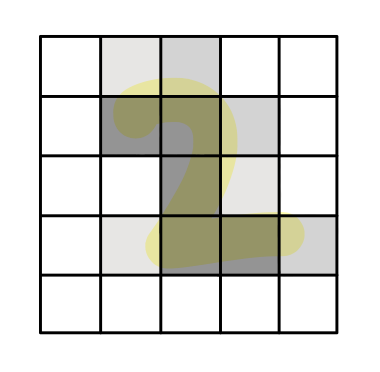
휴대폰 카메라가 1200만 화소라는 말은, 카메라가 사진을 촬영했을 때 위의 2차원
배열의 칸 수가 총 1200만 개라는 의미다. 이 칸을 픽셀(pixel)이라고
하는데, 위의 예시 데이터의 경우 5x5, 즉 25픽셀로 구성되어 있다.
각 픽셀 별로 숫자를 가지고 있는데, 이는 해당 부분의 밝기를 의미한다.
흑백 이미지 데이터의 경우 0에 가까울 수록 검은색, 1에 가까울 수록 흰색을
의미한다.
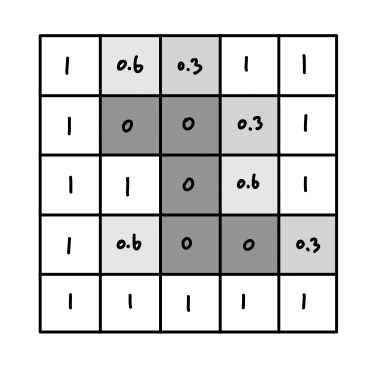
따라서 예시 데이터는 위과 같은 값들을 가지고 있는 2차원 배열이라고 생각하면
된다. 쉽게 살펴보기 위해서 밝기를 의미하는 픽셀값을 0, 0.3, 0.6, 1 이렇게 네
개로만 구성했다.
이제 이 데이터에 어떤 변환을 주어보자.
변환은 간단하다.
필터가 이미지 데이터 위를 돌면서, 같은 위치에 있는 픽셀값끼리 곱한 뒤 더하는
것이다. 2챕터에서 다루었던 가중합과 동일한 연산이라고 생각하면 되는데,
이번에는 데이터가 2차원 배열인 이미지이며 필터가 이동하면서 이미지의 다른
영역과 가중합을 한다는 점에서 차이가 있다. 가중합이 기억나지 않는다면 2.1장으로

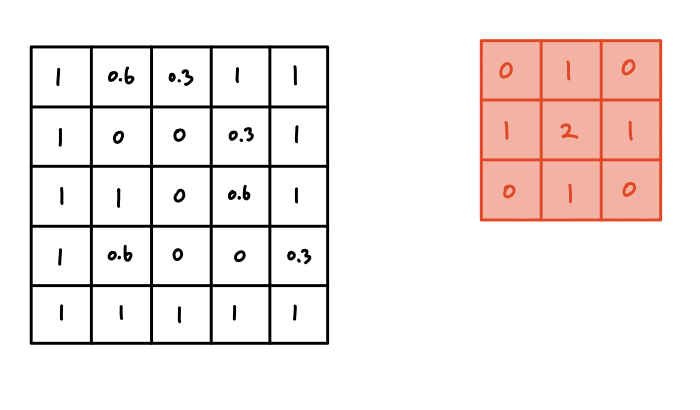
필터가 이미지 데이터의 첫 번째 부분에서 연산한 결과는 위와 같다.
우선 한 줄씩 살펴보자.
이미지 데이터가 해당 위치에 가지고 있던 값들 중
- 첫 번째 행인 [1, 0.6, 0.3]이 필터의 [0, 1, 0]과 각각 곱해져 [0, 0.6, 0]이 나온다.
- 두 번째 행인 [1, 0, 0 ]이 필터의 [1, 2, 1]과 각각 곱해져 [1, 0, 0]이 나온다.
- 세 번째 행인 [1, 1, 0 ]이 필터의 [0, 1, 0]과 각각 곱해져 [0, 1, 0]이 나온다.
- 이 나온 9개의 값들을 모두 더하면 2.6이 된다. 이 값이 이번 연산의 결과다.

다음 연산은 필터가 한 칸 이동한 뒤 실행된다.
필터의 값들은 변하지 않으며, 이동한 필터가 위치하는 부분의 이미지 데이터의
값들과 같은 연산을 한다. 그리고 그 결과는 이전 결과의 한 칸 오른쪽에
저장한다.
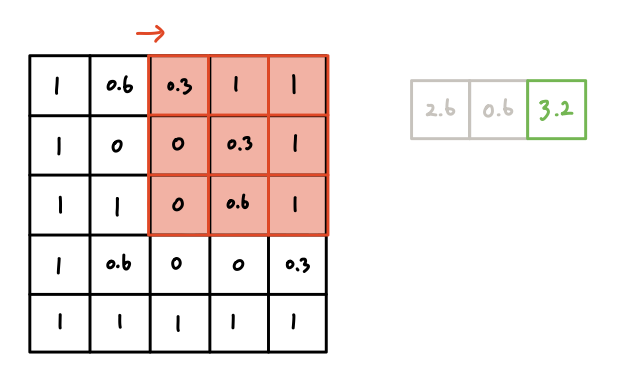
이제 그 다음은 필터가 어디로 이동할까?
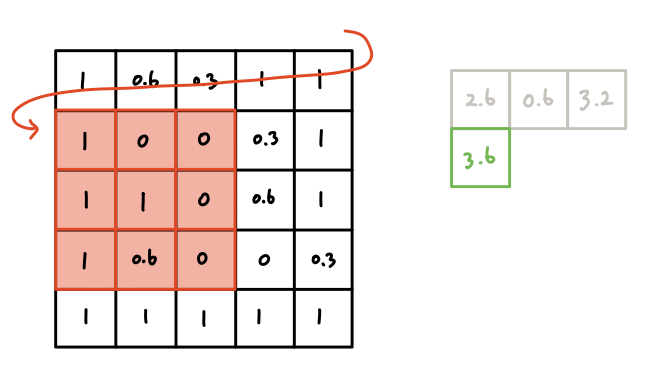
한 칸 밑으로 내려간 뒤, 다시 왼쪽에서부터 이동하게 된다.
이렇게 이미지 데이터의 마지막 부분까지 한 바퀴를 다 돌게 되면, 다음과 같이
3x3 크기의 결과가 나오게 된다.

왜 3x3 크기의 결과가 나왔을까?
생각해보면 간단하다. 가로만 먼저 살펴봤을 때, 5칸 짜리 데이터 위를 3칸 짜리
필터가 한칸씩 지나간다. 그러면 필터가 이미지 데이터의 왼쪽 끝, 정가운데,
오른쪽 끝 세 번 위치하게 되며, 총 3번의 연산이 실행된다.*
* 만약 필터가 1칸씩 이동하지 않고 2칸씩 이동한다면 필터는 이미지 데이터의
왼쪽 끝과 오른쪽 끝 단 두 번만 위치하게 되며, 결과의 크기는 2가 될 것이다.
몇 칸씩 이동할 것인지를 나타내는
매개변수를 스트라이드(stride)라고 한다.
또한, 결과의 크기를 원본 이미지와 동일하게 만들고 싶다면, 원본 이미지
데이터의 가장자리를 0값으로 한 바퀴 둘러주면 된다. 그러면 7x7 크기가 되고,
결과는 5x5가 된다. 이 것을 패딩(padding)이라고 한다.
이렇게 진행되는 연산을 합성곱(convolution)이라고 한다.*

이번에는 다른 필터를 사용해서 동일한 과정을 진행해보자. 필터 안에 다른
값들이 들어 있기 때문에, 앞서 구한 결과와 다를 것이다.
이렇게 필터를 사용해 합성곱 연산을 하게 되면, 각 칸이 단순히 이미지의 1픽셀의
정보를 가지고 있는 것이 아니라, 이미지의 3x3 부분인 9픽셀의 정보를 가지게
된다. 이것이 바로 이미지 데이터에 대해서 합성곱 신경망이 잘 동작하는 이유라고
할 수 있다. 이미지를 단순히 각각의 픽셀들로 1개씩 정보를 받아들이는 것이
아니라, 필터들을 사용해 상하좌우 주변의 픽셀들을 동시에 보겠다는
것이다.
다시 말해 필터를 사용해 나온 결과 배열은, 이미지를 필터 크기만큼의 픽셀을
동시에 보면서 추출된 특성이라고 할 수 있다. 하나가 아닌 여러 개의
필터를 사용한다면, 여러 개의 특성을 추출하게 된다.
즉, 우리가 알고 있는 신경망 모델의 구조가 나타난다. 신경망이 잘 기억나지 않는다면 2.6장으로

하나의 필터를 통해 나오는 결과 배열을 특성맵(feature map)이라고 한다.
출력되는 특성맵의 수를 채널(channel) 수*라고 표현한다. 3개의 필터를
사용한다면 출력 채널 수가 3이 되고, 10개의 필터를 사용한다면 출력 채널 수가
10이 된다.
* 같은 크기를 가지는 2차원 배열 데이터가 여러 겹 있다는 말은, 여러 채널로
구성된 하나의 3차원 배열 데이터가 있다는 것으로 볼 수도 있는 것이다.
이미지를 예시로 들어보면, 우리의 예시에서는 1채널(흑백) 이미지를 입력으로
사용했지만, 컬러 이미지 데이터의 경우 붉은색, 초록색, 푸른색(RGB) 세 개의
채널이 존재한다.
일반적으로 합성곱 신경망의 구조를 표현하는 그림으로 표현하면 다음과 같다.

그런데 필터에는 어떤 값이 들어가야 될까?
딥러닝이 등장하기 전에는 이 필터의 값들을 정해놓고 사용했다. 포토샵이나 사진
편집 앱에서 "선명하게" 효과를 사용해본 적이 있는가? 이는 선명 효과
필터(sharpen filter)*를 사용한 것이다.
* 우리가 위에서 사용한 붉은 색의 필터의 값들에서 1을 모두 -1로 바꾸면
선명 효과 필터가 된다. 이 장 마지막 부분에 여러 가지 필터들이 어떤 값들로
구성되어 있고, 이미지가 어떻게 변환되는지 시각적으로 확인할 수 있는
웹페이지 링크를 적어놓았으니 꼭 확인해보기를 바란다.
하지만 딥러닝에서는 필터의 값들이 정해져 있지 않다. 학습의 원리는 가중치의
값들이 점점 더 좋은 예측을 하는 방향으로 변해가는 것이며, 합성곱
신경망에서는 바로 이 필터의 값들이 가중치라고 보면 된다.

즉, 우리는 학습을 시작하기 전에 신경망의 몇 층에서 몇 개의 필터를 사용할
것인지는 미리 정해놓지만, 그 필터들의 값들은 학습을 진행하면서 계속 바뀌게
된다. 필터의 값들이 최적화되면서, 더 유의미한 특성맵이 추출되고, 그로 인해
예측의 정확도가 높아지는 것이다.

|
|
합성곱 신경망도 결국 신경망이다. |

이번 장에서는 합성곱 신경망에 대해서 알아보았다.
이로서 <비전공자를 위한 딥러닝>의 모든 내용을 끝마치게 되었다. 다음
장에서는 다음 단계로 좋은 책과 강의를 추천하면서 책을 마무리한다.
더 알아보기
- Image Kernels Explained Visually
- 여러 가지 필터 변환을 시각적으로 체험할 수 있는 곳
- 3D Visualization of CNN
- CNN 구조를 입체적으로 보며 손글씨 인식을 직접 테스트할 수 있는 곳
- 합성곱 신경망(CNN) 역전파까지 5분만에 이해하기
- 스탠퍼드 cs231n 강의 노트: CNN의 구조 [한글] [영어]

![[책&강의] 직접 보고 추천하는 머신러닝 & 딥러닝 & 수학 총정리 (2022)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg4J7BS4klgeMe-qrWTi8NgyI_4TLzPs_ltwFp4591fHoi8fOXITF_0JXLzcFeN9zIMaFPfpO-PpPOl6gej6pA4uRAWBhKMna9DJsNtTW2IbnIn3a2z_xa54Oyn8evu1P0GKQpElxZgMTI/w680/ml%25EC%25B4%259D%25EC%25A0%2595%25EB%25A6%25AC.jpg)
![[비전공자를 위한 딥러닝] 2.2 선형회귀 (2) - 오차와 비용](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjEhHlP2edVHNaiochUISyW2RIQ_K5Kdsh0gjT5Wt1vY4nH7uP_0mTNZ1suzBRmpsPOptT1n4-hJ1mOXUhY4ZvLyiywxqn_7wusQDpllIS94VPVuYbQqpCdyuhISZ2mYNQF6laTKDUk_ts/w680/%25E1%2584%2587%25E1%2585%25B5%25E1%2584%258C%25E1%2585%25A5%25E1%2586%25AB%25E1%2584%2580%25E1%2585%25A9%25E1%2586%25BC%25E1%2584%2583%25E1%2585%25B5%25E1%2586%25B8%25E1%2584%2585%25E1%2585%25A5%25E1%2584%2582%25E1%2585%25B5%25E1%2586%25BC2.jpg)
![[꿀팁] M1 맥북 캡스락/커맨드키 한영전환 딜레이/에러 완벽해결 (부팅 에러나는 karabiner 없이)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiuErCCNiCMKeemRrnSwMB_8gGjyJs-AbEfFDDA5joDoDVKNiNgnxEUd2XMmegPyZC5dGU4XAj_Zv8gQwF_MwhuLlQNPNQyga8x7zcs3_RrfPP-nIT4kWmO8kUd9MiiFBoEvxlM_S5GgAA/w680/KakaoTalk_Photo_2021-01-17-05-12-09.jpg)

![[QnA] 네이버 부스트캠프 AI Tech 취뽀했습니다 질문 받습니다](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgJdAPI1j2bMdLAz3p-qJ3TSGqsjQte_vo8jtMXIaB1Sf1IKaFG_w4SiHE5LT0kxc7-lgVQt7QB6O7NDDQZGBKXrw3SsKje4g6j2BFLLmT0ZX0nuJ40HWCDR_c3I-9M6rcN1eduvYP-lt4/w680/a.jpg)
![[비전공자를 위한 딥러닝] 2.4 신경망 (2) - 가중치 행렬 한방에 이해하기](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiYj8FRyvmF70qt64R3suVR6lJdNynz2-tF5fa7T_3wE8SK3KIO1BCvwyypr5J_mlxaYkQjadrofLYsMjBbgRklxDORXoWiJdWP79otQowzIXsghxuZS9aYLhvvlMNX3NzQ3VYDdslwmbk/w680/%25E1%2584%2587%25E1%2585%25B5%25E1%2584%258C%25E1%2585%25A5%25E1%2586%25AB%25E1%2584%2580%25E1%2585%25A9%25E1%2586%25BC%25E1%2584%2583%25E1%2585%25B5%25E1%2586%25B8%25E1%2584%2585%25E1%2585%25A5%25E1%2584%2582%25E1%2585%25B5%25E1%2586%25BC2+%25281%2529+%25E1%2584%2587%25E1%2585%25A9%25E1%2586%25A8%25E1%2584%2589%25E1%2585%25A1%25E1%2584%2587%25E1%2585%25A9%25E1%2586%25AB+3.jpg)
0 댓글